Data is abundant. Decision velocity is not. Most enterprises already have data lakes, warehouses, BI tools, and ML stacks. The constraint isn’t access to data, it’s turning that data into trusted, governed, and reusable assets that analytics, engineering, and AI teams can operate on together.
Fragmented platforms force teams to duplicate data, rebuild pipelines, and manage inconsistent governance. As AI adoption accelerates, these inefficiencies compound.
This is the problem Databricks was built to solve.
What is Databricks?
Databricks is a unified data analytics and AI platform designed to run data-engineering, analytics, and machine learning workloads on a single Lakehouse architecture. Instead of separating data lakes, warehouses, and ML platforms, Databricks consolidates them on cloud object storage, allowing teams to move from ingestion to insight to AI without copying data across systems.
The platform integrates directly with your cloud provider’s security and storage services while automatically managing compute provisioning, scaling, and performance optimization.
In practical terms: your data stays in your cloud, while Databricks orchestrates how it’s processed.
The architectural problem Databricks addresses in traditional enterprise environments
- Data is repeatedly moved between lakes, warehouses, and ML systems
- Ownership is fragmented across teams
- Governance is applied inconsistently
- Costs rise as pipelines multiply
Databricks addresses this by applying warehouse-grade reliability and performance to open data alake storage, eliminating the need for parallel systems.
The result is a single source of truth that supports BI, Analytics, and AI workloads without duplication.
What can you do with Databricks?
Databricks replaces complex, multi-tool analytics stacks with a single operating layer for Data and AI. Organizations commonly use it to:
- Centralize data ingestion across batch and real-time streams
- Clean, transform, and organize data at scale
- Run large-scale computation and advanced analytics
- Enable governed self-service analytics for business teams
- Train, deploy, and monitor machine learning models
- Power dashboards, reporting, and AI-driven decisioning
This consolidation is what makes the Databrcicks unified data analytics platform operationally efficient.
Who benefits from Databricks?
Large enterprises, small businesses, and mid-sized businesses use the Databricks platform today. Many international brands, such as Microsoft, Coles, Apple, Shell, HSBC, Atlassian, and Disney, use Databricks to manage their data demands efficiently and swiftly.
Databricks’ exceptional performance and breadth make it useful for all data teams, including data analysts, data scientists, machine learning engineers, data engineers, and business intelligence experts. This versatility helps explain what Databricks does for businesses across industries, from data ingestion to advanced analytics.
Read more: How Databricks teams up with Microsoft Fabric for smarter data solutions
Databricks vs. data warehouse vs. database
Traditional databases and warehouses are optimized for fast querying on structured data.
Databricks is optimized for high-throughput processing and advanced analytics.
Built on Apache Spark, Databricks efficiently handles:
- Large-scale transformations
- Complex joins and aggregations
- Streaming and batch workloads
- Machine learning pipelines
To enhance performance further, Databricks introduced Photon, a vectorized query engine that accelerates SQL workloads while retaining Spark’s flexibility.
The key difference, however, lies in storage: Databricks separates compute from storage, keeping data in open formats on cloud object storage, avoiding lock-in.
Take control of your business operations
Discover how Confiz services can simplify your complex workflows and improve decision-making.
Get a Free QuoteCapabilities that shape how Databricks operates at scale
Databricks is designed around a small set of capabilities that determine how analytics and AI workloads behave under enterprise conditions. These capabilities focus on consolidation, governance, and consistent execution rather than feature breadth.
1. Data connectivity
Databricks links to a massive amount of data sources that aren’t restricted to Google Cloud, AWS, or Azure storage services but also include CSV, JSON, and on-premises SQL servers. It also supports Avro files, MongoDB, and multiple other file types.
2. Multi-language development
This platform has a notebook interface that lets you use multiple programming languages in a single environment. You can build R, SQL, Python, or Scala algorithms by utilizing simple commands. Data transformation processes can be carried out using model predictions generated in Scala, data displayed in R, and model performance analyzed in Python.
3. Flexibility
Databricks was built on Apache Spark, which has the core capability for cloud-based deployments. This platform offers scalable Spark processes for managing small-scale tasks such as testing and development, as well as large-scale processes for data science.
4. Team productivity
Databricks’ unified data analytics platform increases productivity by enabling users to deploy notebooks into production instantly. The platform offers collaboration through a shared workspace for business data analysts, data engineers, and scientists.
How Databricks operates under enterprise conditions
Databricks is structured around a set of operational choices that determine how analytics and AI workloads behave at scale. These choices focus on execution of consistency, storage of ownership, and governance rather than feature differentiation.
1. Cloud execution model
Databricks was built with cloud-based deployment in mind and can manage many cloud-native scenarios. This platform uses Kubernetes to orchestrate containerized workloads for data processing and product microservices.
2. Storage model
Databricks keeps data tables and files in the cloud via object storage. It creates a cloud object storage location, also called the DBFS root, across workspace deployments. You can configure connections in your account to multiple cloud object repository sites.
3. Lakehouse architecture
Data lakes are known for their open formats, which allow users to avoid lock-in to a proprietary system like a data warehouse. With the capacity to expand and use object storage, a data lake is low-cost and long-lasting. Databricks offers data lake features and is a great choice for storage because it supports storing raw data in various formats.
4. Governance & management
With unique features such as Databricks Delta Sharing and Unity Catalog, Databricks offers centralized data governance. Delta Sharing allows you to share data, and Unity Catalog unifies access control. Other capabilities include IAM, legacy data governance, and audit tracking.
5. Datascience and AI execution
Databricks is best used to process, clean, store, share, model, and monetize data with various solutions, including business intelligence and data science. This platform supports several data science use cases.
Accelerate growth at an unprecedented pace
Discover how Confiz can help you take control of your daily operations, increasing growth and revenue.
Book a Free ConsultationWhere Databricks fits in the data lifecycle
Databricks is designed to support analytics, engineering, and machine learning workloads without forcing data movement between systems. Each workload operates on the same underlying data foundation.
1. SQL analytics
Databricks SQL provides SQL-based access to Lakehouse data and integrates with downstream BI tools such as Tableau and Microsoft Power BI. Query execution is handled by a managed compute service that scales with demand. Parallel execution reduces contention as concurrency increases, supporting consistent performance under load.
2. Data engineering
Powered by Apache Spark, Azure Databricks gives data engineers and analysts the tools to build and run scalable data workflows. Whether you’re processing, analyzing, or visualizing large datasets, it’s built to handle heavy lifting. Delta Lake is an open-source storage layer that adds reliability and structure, helping you create robust Lakehouse architecture on top of Spark.
With the Databricks Lakehouse Platform, data engineers can:
- Design and manage end-to-end data pipelines
- Use SQL and Python to extract, transform, and load data into Lakehouse tables and views
- Leverage built-in tools like Delta Live Tables to simplify data ingestion and manage updates
- Power real-time analytics and dashboards by orchestrating production-grade workflows
3. Machine learning & data science
Databricks provides an integrated environment for model development, training, and deployment. It includes runtimes optimized for machine learning and supports common frameworks such as TensorFlow, PyTorch, Keras, and XGBoost, as well as distributed training via Horovod. This allows models to scale without introducing separate infrastructure or execution paths.
Databricks architecture
Databricks is built to support secure, cross-functional collaboration, so teams can stay focused on data science, analytics, and engineering, without getting bogged down in backend complexity.
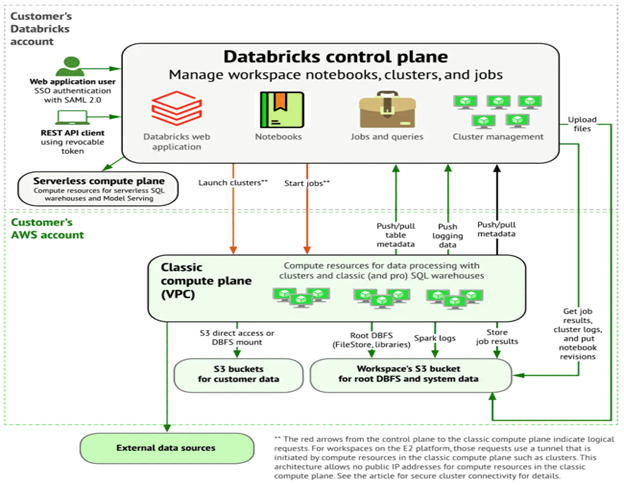
Under the hood, Databricks runs on a two-plane architecture: the control and data planes.
The control plane handles core services and workspace management. Databricks operates in its cloud account and stores things like notebook commands and workspace metadata, which are encrypted at rest for security.
The data plane is where your actual data lives and gets processed. Importantly, your data remains in your cloud account, at rest and during processing. Even job results are written back to your storage, always keeping you in control of your data.

Getting started with Databricks
Databricks is an architectural choice that shapes how analytics and AI operate at scale. Its relevance lies in reducing fragmentation across data engineering, analytics, and machine learning while maintaining control over storage, governance, and execution.
For organizations consolidating their data platforms, the outcome depends less on tooling and more on how deliberately the Lakehouse model is designed and operationalized.
Confiz offers Databricks consulting services to help you plan, implement, and optimize your data solutions. Contact us at marketing@confiz.com to explore more.








