Data management is a challenge for organizations worldwide as they grapple with growing volume, variety and complexity of data. While businesses emphasize autonomy and productivity, they are still stuck with siloed data and monolithic architecture that leaves them drowning in a data lake and struggling to extract valuable insights. A survey showed that approximately 50-70% of data generated and stored by organizations remains unused, transforming into what Gartner calls “dark data.”
To address the dynamic requirements of modern businesses and effectively manage data across complex and distributed environments, organizations often turn to two prominent data architecture approaches i.e., Data Fabric and Data Mesh. These innovative data management approaches serve as a promising solution to break down silos and facilitate the extraction of actionable insights from the vast trove of data.
But the question remains: Which approach is better for your organization to make informed decisions and manage data at scale? This blog explains both Data Mesh and Data Fabric while highlighting the differences and benefits of each approach to help you determine which fits your organization’s needs.
What is a Data Fabric?
Gartner defines Data Fabric as,
“A design concept that serves as an integrated layer (fabric) of data and connecting processes.”
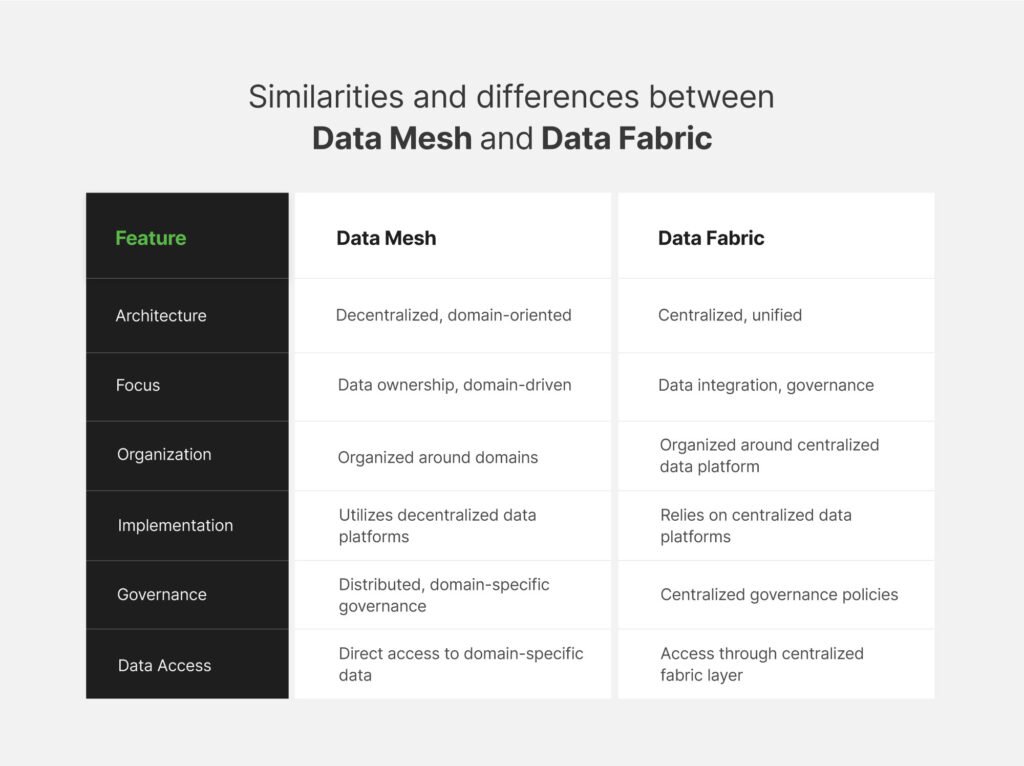
Data Fabric architecture is a centralized data management, governance, and processing approach. This approach supports end-to-end integration of diverse data sources through cutting-edge AI/ML technologies. Data fabric solutions aim to create a unified data layer across the entire organization for easy access and processing to ensure quality, consistency, and security.
The most important thing about Data Fabric is its architecture and the array of data services it encompasses. Data fabric ensures a smooth exchange of information across various platforms, whether storing data on-premises, in the cloud, or in a hybrid environment. This flexibility ensures that data, regardless of its format or location, stays integrated and readily accessible.
Gartner reports that Data fabric reduces integration design time by 30%, deployment time by 30%, and maintenance time by 70%. While it’s clear that using Data Fabric boosts productivity, empowering both businesses to make rapid decisions and focused expertise utilization.
However, the main characteristic of this centralized approach includes:
- Centralized governance
- Data visualization
- Unified view
- Integration-centric
- Data protection
What is Data Mesh?
Zhamak Dehghani, a principal consultant at Thoughtworks, introduced Data Mesh in her 2019 article titled “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh,” followed by the December 2020 report titled “Data Mesh Principles and Logical Architecture.”
Furthermore, Zhamak Dehghani promotes data mesh to address challenges posed by centralized, monolithic data structures, like accessibility and organization.
IBM defines Data Mesh as,
“Decentralized data architecture that organizes data by a specific business domain—for example, marketing, sales, customer service, and more—providing more ownership to the users.“
Instead of centralized, monolithic, and traditional storage systems like data warehouses or lakes, Data Mesh promotes domain-oriented and self-service infrastructure. This means individual teams or departments can access multiple decentralized data repositories.
The reason that many businesses embrace Data Mesh is because it provides improved access control and governance, reducing bottlenecks. The Date Mesh architecture is built upon four principles:
- Domain-oriented ownership
- Data as a product
- Self-service data infrastructure
- Federated computational ecosystem