Gone are the days when businesses acquired data warehouses to collect data from multiple sources to fuel their data analytics. When the concept of data lakes was introduced in 2011, it created a revolution in the way data is gathered and stored. Today, businesses emphasize data and AI and have shifted toward data integration using data lakes for easier data analysis, to make better data-driven decisions, promote data consistency, and improve data quality and integrity.
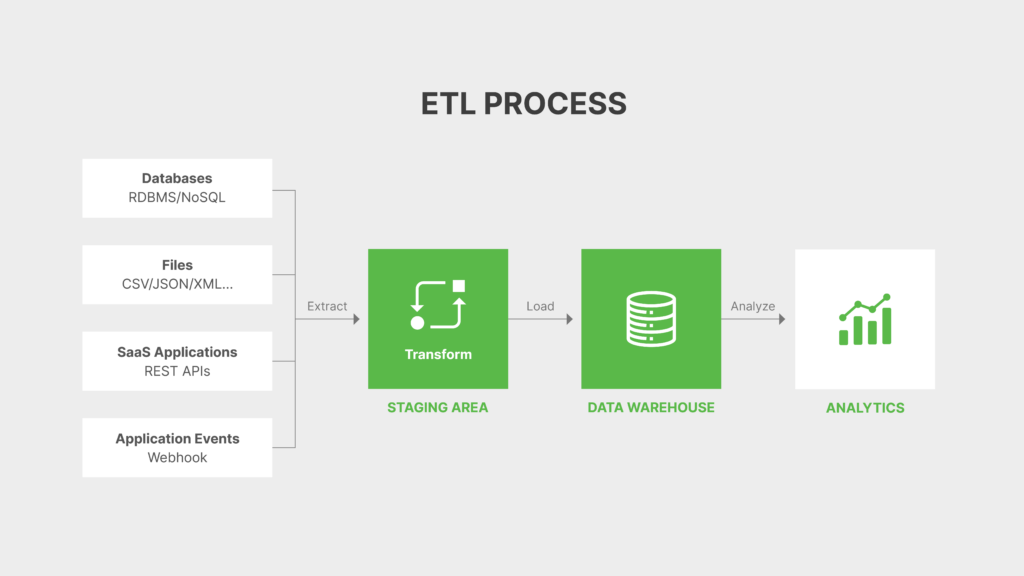
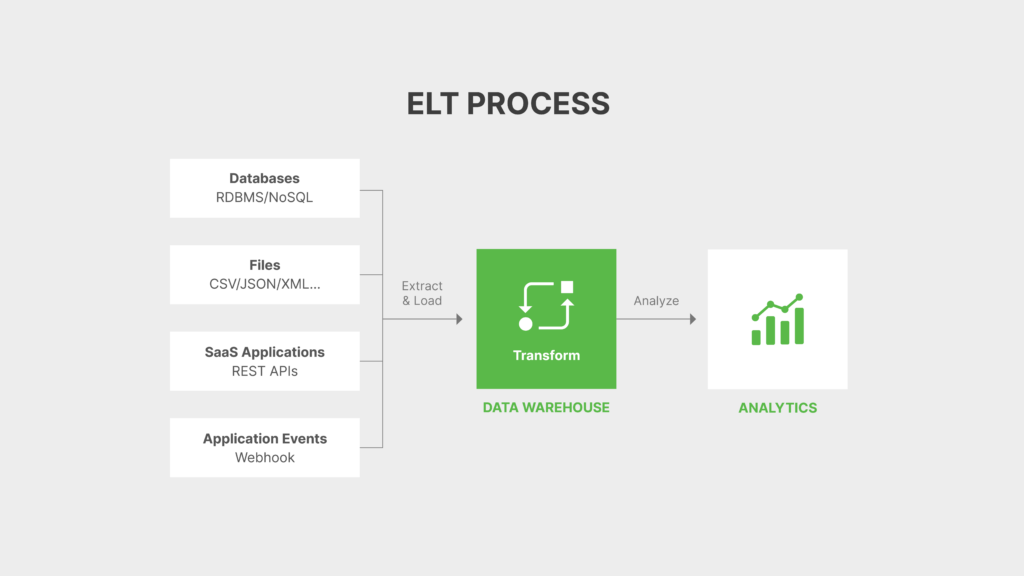
Times have progressed further, and businesses now have access to virtually unlimited, inexpensive cloud storage to load data. This has led to the emergence of new frameworks for extracting, integrating, and processing data through the use of pipeline workflows, APIs, and data shared from remote, cloud-based storage locations i.e. ELT (Extract, load, transform) and ETL (extract, transform, and load).
Key insights from the data integration market study reveal that organizations are very focused on data integration to support analytics and Business Intelligence initiatives companywide. This heightened focus is substantiated by a report highlighting that effective data integration enhances business decisions by up to 90%.
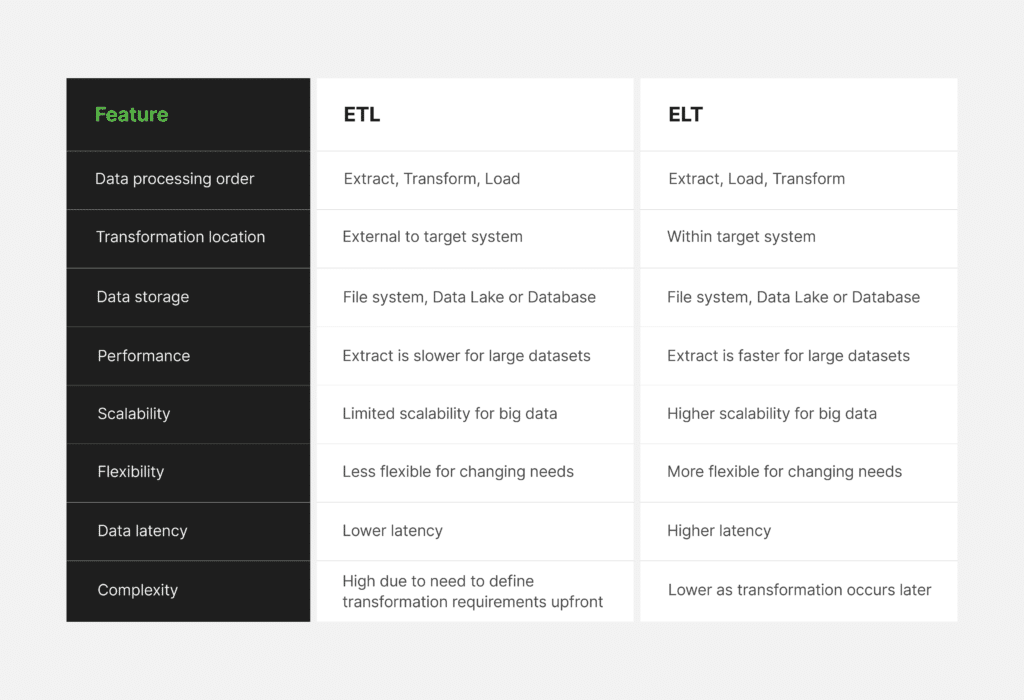
Organizations generate vast amounts of data on a minute-by-minute, hourly, and daily basis. Capturing, integrating, structuring, and analyzing data for decision-making poses significant challenges. In addressing these challenges, ETL and ELT approaches perform similar tasks, but there are important differences that can limit the use of data for future use cases and have cost implications.
Through this blog, we will explore these data integration strategies in detail. Also, we will delve into their processes and their pros and cons to help you choose the right approach for data projects with confidence.
Understanding the data integration process and the role of ETL and ELT
Since a data integration solution involves transferring or accessing data from one system to another, it requires a method to access data that can also orchestrate the movement, curation, and transformation of data. However, the specific techniques that businesses may use for data integration depend on the following factors:
- Data volume, velocity, and variety
- Number and type of data sources and destinations
- Requirements or desire to preserve historical data for future (unknown) use cases
- Data engineering resources, skill levels, and time available
- Available toolsets and technologies (cloud provider, vendor tools, IT resources)
- Data security and compliance requirements
The most common process within data integration is data ingestion (extraction or access), where one source system regularly ingests data into or accesses data from another system. Integrating data, also often requires data cleansing, validation, and enrichment to prepare data for analysis.
As an example of how the approaches differ in performing similar tasks, ETL and ELT approach data cleansing in the following manner. ETL (extract, transform, load) cleans data before storing (loading) data for future use, while ELT (extract, load, transform) stores data first and then cleans it.
While these differences may seem minor they are not. For example, cleansing or changing data before storing it impacts the potential future use of historical source system data. After the data modification, it is no longer an accurate point-in-time representation of the source data.
Conversely, storing the data in its raw form, without changes, preserves all data for future use cases. For example, you may need a data column only in the future for a new yet unplanned analytics solution. Another example would be a machine learning experiment that uses all historical data across a wide range of time.
While both integration methods perform similar pivotal tasks, the fundamental differences between the two methods have significant implications for data processing, storage, and analytics.