As artificial intelligence continues to transform industries, its ability to uncover deeper insights and enable smarter choices is rooted in how effectively it processes complex data. The emphasis is no longer just on processing data but to understand and interpret information in ways that mirror human intuition. This shift is paving the way for smarter, more personalized solutions that redefine how technology interacts with people and businesses in the age of data and AI.
At the core of this capability lies embedding—a transformative approach that enables AI systems to process and analyze data in ways that mirror human understanding. Whether it’s powering recommendation systems, enabling natural language processing, or driving personalization, LLM embedding provides a bridge between raw data and intelligent decision-making.
This blog explores the transformative role of embeddings in AI, their applications across various domains, and the processes behind setting up an embedding pipeline. Additionally, we explore real-world examples that highlight their practical impact, making a compelling case for their role in revolutionizing AI-driven solutions.
What is embedding?
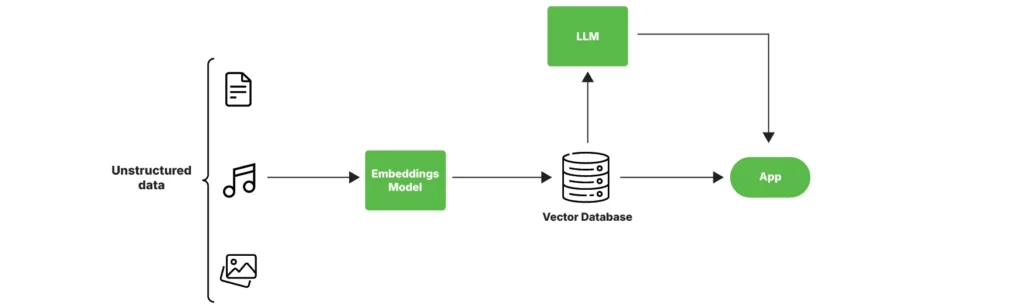
An embedding is a numerical representation of data, typically in the form of a vector, that captures the meaning, relationships, and context within that data. It serves as a way for machines to understand complex information by converting unstructured data like text, images, or audio into a structured format that is easier for algorithms to process. These embedding vectors are then stored in a vector database and passed down to an LLM which splits the original unstructured data into a structured format.
Embeddings can be applied to different data types. The most common types of embedding models include word embedding, text embedding, image embedding, audio embedding, and graph embedding.
An example of embedding from our daily life
A simple example of embeddings in AI is how Spotify recommends songs based on your listening habits.
How it works
- Each song is converted into a numerical representation (embedding) based on features like genre, lyrics, tempo, and user listening patterns.
- Similar songs will have embeddings that are closer together in this numerical space.
- When you play a song, Spotify finds other songs with similar embeddings and recommends them to you.
So, instead of just looking at genre or artist, AI understands relationships between songs based on patterns – thanks to embeddings!
Why use embeddings?
Embeddings transform complex data (like text, images, or user behavior) into meaningful numerical representations that AI models can easily process. Some key features of embedding that explain why they are useful are explained below:
- Dimensionality reduction
They reduce complex data into smaller, fixed-size numerical representations, simplifying analysis and computation.
Instead of processing raw text or images, embeddings convert them into compact vectors, reducing computational complexity. For example, AI in recommendation systems (like Netflix or Amazon) can process millions of items faster using embeddings.
- Contextual representation
Embeddings capture relationships and context. For example, in natural language processing (NLP), similar words like “car” and “vehicle” will have vectors that are close to each other in the embedding space.
- Versatility
They are used across various domains, including text (e.g., word embeddings), images, and audio, to enable tasks like search, recommendation, and clustering.
Read more: LLM vs Generative AI: How each drives the future of artificial intelligence.