The growing volume of data from various sources has made data science a rapidly growing field across every industry. This interdisciplinary field uses algorithms, processes and procedures to examine large volumes of data and uncover patterns and insights for analysis and decision making. Consequently, it comes as no surprise that the demand for skilled data scientists is projected to surge by 36% between 2021 and 2031.
Microsoft Fabric, an end-to-end analytics service, provides data scientists with a versatile toolkit to perform various tasks in data analysis and machine learning. From data exploration, preparation, and cleansing to experimentation, modeling, and generating insights through BI reports, MS Fabric empowers users to efficiently manage data science workflows.
With Microsoft Fabric, businesses have a powerful platform at their disposal to make the most out of their data on a broader scale and gain valuable insights to drive informed decision-making.
With tools like Notebook, Data Wrangler, Power BI, and Visual Studio Code, Microsoft Fabric offers several opportunities for data scientists to assist organizations in solving complex problems, optimizing processes, and discovering new opportunities. Through this blog, let’s delve into the capabilities of data science within the Microsoft Fabric environment.
What is Data Science?
Data science involves extracting insights, patterns, and knowledge from different data sources (structured and unstructured) to analyze large data sets and derive actionable insights. Data science combines Machine Learning, Artificial Intelligence, advanced analytics, and specialized programming to discover hidden patterns and trends within data.
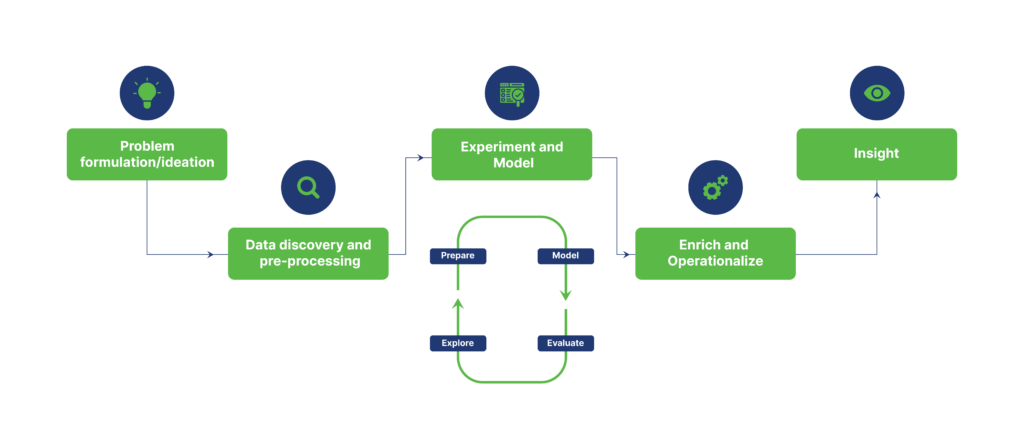
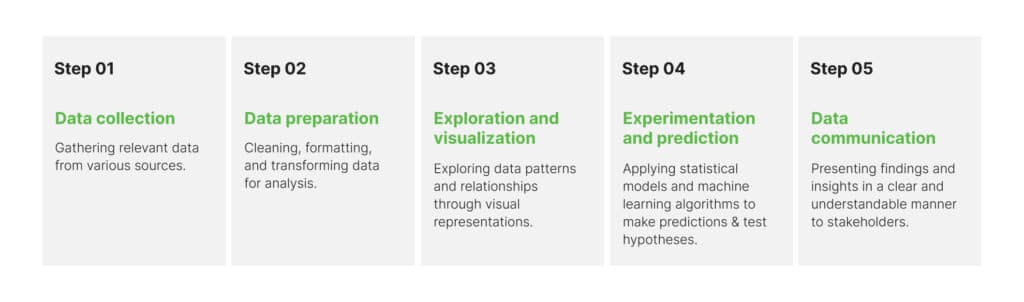
Since data science involves extracting valuable information from vast and complex data sets, it follows a specific lifecycle. This data science lifecycle outlines the five different stages involved in transforming raw data into actionable insights, including:
- Data collection
- Data preparation
- Exploration and visualization
- Experimentation and prediction
- Data communication
The Data Science experience within the Microsoft Fabric environment
In Microsoft Fabric, business users can access data science features to facilitate the completion of comprehensive data science workflows, serving the purposes of data enrichment and business intelligence. From conducting data exploration, preparation, and cleansing to engaging in experimentation, modeling, and delivering predictive insights within BI reports, users are equipped with a wide range of capabilities to make informed decisions and acquire the maximum potential of their data assets.
Microsoft Fabric users are granted access to a centralized hub known as the Data Science Home page, offering an array of valuable resources at their fingertips. This platform is designed for convenience and efficiency, allowing users to generate machine-learning Experiments, Models, and Notebooks with ease. Furthermore, users can import existing notebooks directly from this centralized location, saving them time and effort.