Extracting meaningful insights from a diverse data pool is daunting for data-driven organizations. Traditional data storage solutions often struggle to provide the necessary structure and arrangement for effective analysis. Here, Microsoft Fabric, with its data warehousing capabilities, offers a compelling solution to help you manage, store, and analyze your data.
Microsoft Fabric’s data warehouse is revolutionizing the traditional data warehouse concept by offering a unified and AI-powered platform for data management and analytics. This scalable platform allows organizations to break down data silos and consolidate their data assets into a single, cohesive repository to gain a comprehensive view of their data landscape.
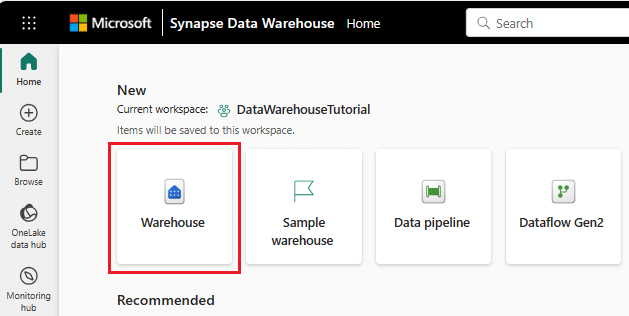
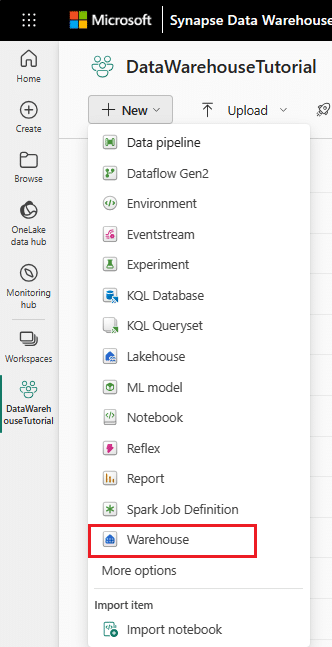
Getting started with a data warehouse and creating your own warehouse in Fabric Microsoft is simple. This blog post explains the concepts of data warehouses in Microsoft Fabric and explores its multiple functionalities and offers a comprehensive guide to building your first warehouse within the Fabric ecosystem.
Data warehouse experience in Microsoft Fabric
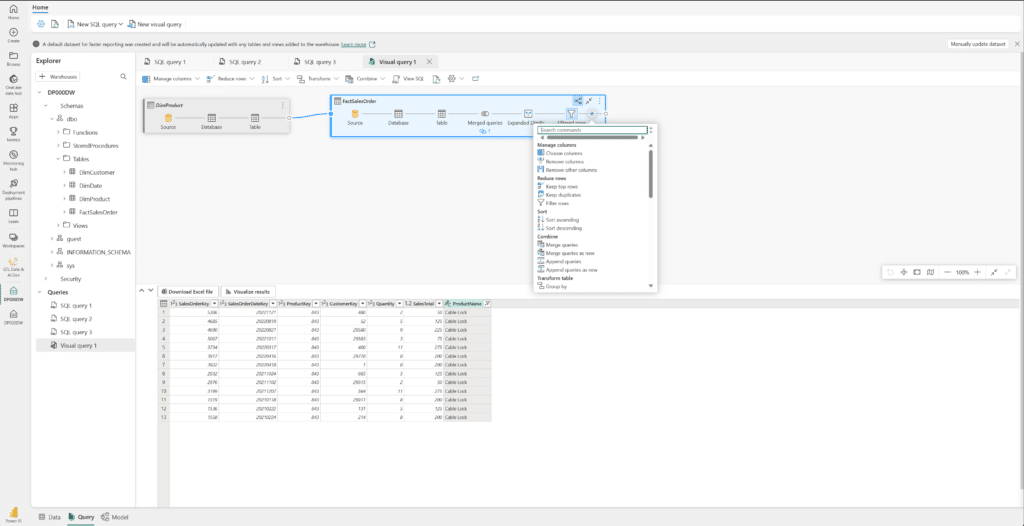
The data warehouse in Microsoft Fabric is a fully managed, scalable, and highly available data warehouse that allows users to store and query data in the Lakehouse. With a user-friendly SaaS experience that seamlessly integrates with Power BI, a powerful Business Intelligence tool, for effortless analysis and reporting, warehouse in Fabric combines data lakes and warehouses to simplify the investment required for an organization’s analytical infrastructure.
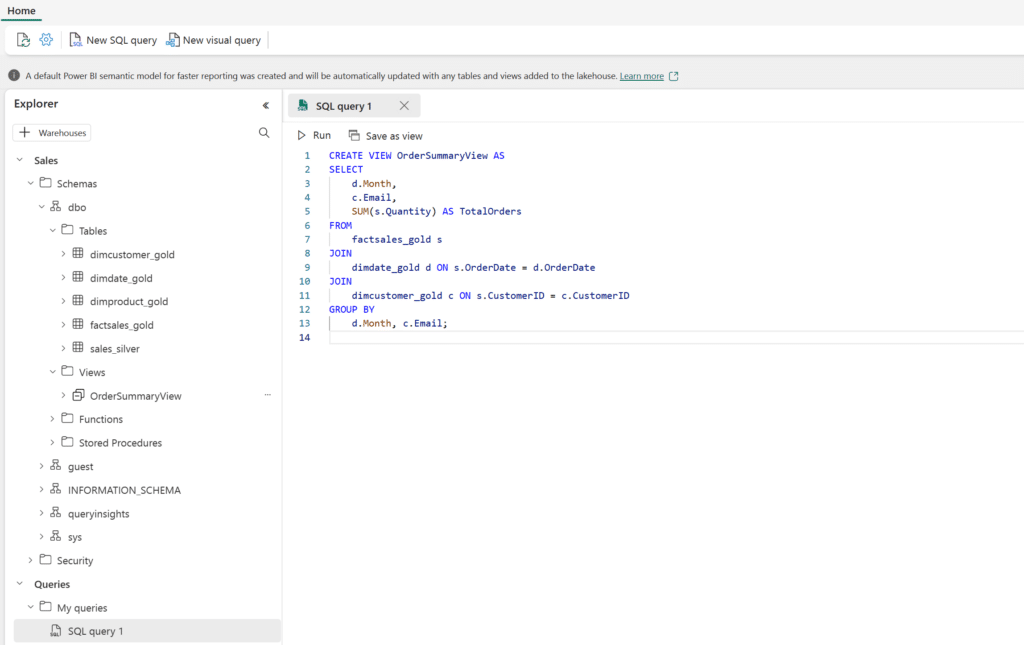
With a data warehouse, users can create tables, load, transform, and query data through the Fabric portal and T-SQL commands. They can either use SQL to query and analyze the data or opt for Spark to handle data processing and the creation of machine learning models.
Within Fabric’s data warehouses, data engineers and analysts collaborate seamlessly within a unified environment. Data engineers build a structured layer (relational layer) on the Lakehouse, allowing analysts to use T-SQL and Power BI for thorough data exploration.
Further readings: Explore the key differences between data lake and data warehouse.
Types of Data Warehouse in Microsoft Fabric
Microsoft Fabric offers two distinct types of data warehousing. These includes the SQL analytics endpoint of the Lakehouse and Synapse Data Warehouse.
Type 1: SQL endpoint of the Lakehouse
Microsoft Fabric offers a unique feature: the SQL analytics endpoint. This endpoint essentially functions as a data warehouse automatically generated from Lakehouse in Microsoft Fabric. Users can seamlessly transition between two data access methods within the same Lakehouse:
- Lake view: This view caters to data engineering and Apache Spark.
- SQL view: The SQL analytics endpoint operates in read-only mode, with data modification exclusively accessible through the “Lake” view using Spark.
The SQL analytics endpoint within the Lakehouse offers a subset of SQL commands specifically designed for defining and querying data objects. However, data manipulation (create, update, delete) functionalities are not supported through this interface.
- Users can perform the following series of actions in the SQL analytics endpoint.
- Query the tables that reference data in your Delta Lake folders in the lake.
- Create views, inline TVFs, and procedures to encapsulate your semantics and business logic in T-SQL.
- Manage permissions on the objects.
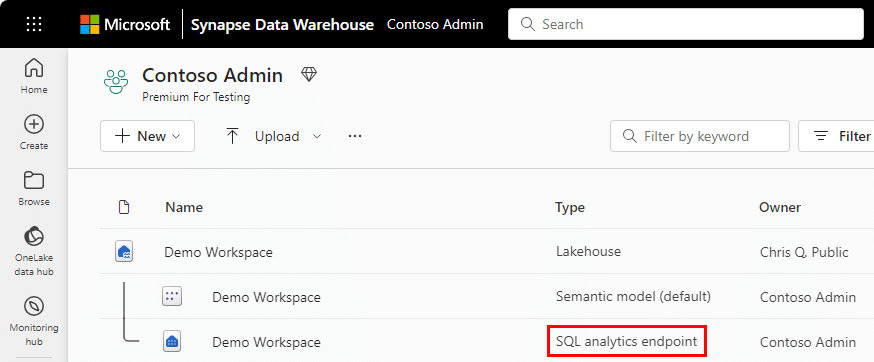
The SQL analytics endpoint is readily identifiable within the Microsoft Fabric workspace by the label “SQL analytics endpoint” displayed in the “Type” column. Every Lakehouse is equipped with an automatically generated SQL analytics endpoint, accessible through familiar SQL tools like SQL Server Management Studio, Azure Data Studio, and the Microsoft Fabric SQL Query Editor.
Type 2: Synapse Data Warehouse
Data warehouses within the Microsoft Fabric workspace are clearly distinguished by the “Warehouse ” label displayed in the “Type” column. Compared to SQL endpoints, these warehouses offer a broader range of functionalities. They support querying data (DML), enable data definition tasks (DDL), and even handle transactions.
While SQL endpoints within Microsoft Fabric are limited to read-only queries, view creation, and temporary function definition, warehouses provide a more comprehensive feature set. Notably, warehouses are user-created and fully support transactional DDL and DML operations. Data population within warehouses can be achieved through various supported methods, including COPY INTO, pipelines, dataflows, or even cross-database ingestion techniques like CREATE TABLE AS SELECT (CTAS), INSERT..SELECT, or SELECT INTO.