

Gone are the days when businesses acquired data warehouses to collect data from multiple sources to fuel their data analytics. When the concept of data lakes was introduced in 2011, it created a revolution in the way data is gathered and stored. Today, businesses emphasize data and AI and have shifted toward data integration using data lakes for easier data analysis, to make better data-driven decisions, promote data consistency, and improve data quality and integrity.
Times have progressed further, and businesses now have access to virtually unlimited, inexpensive cloud storage to load data. This has led to the emergence of new frameworks for extracting, integrating, and processing data through the use of pipeline workflows, APIs, and data shared from remote, cloud-based storage locations i.e. ELT (Extract, load, transform) and ETL (extract, transform, and load).
Key insights from the data integration market study reveal that organizations are very focused on data integration to support analytics and Business Intelligence initiatives companywide. This heightened focus is substantiated by a report highlighting that effective data integration enhances business decisions by up to 90%.
Organizations generate vast amounts of data on a minute-by-minute, hourly, and daily basis. Capturing, integrating, structuring, and analyzing data for decision-making poses significant challenges. In addressing these challenges, ETL and ELT approaches perform similar tasks, but there are important differences that can limit the use of data for future use cases and have cost implications.
Through this blog, we will explore these data integration strategies in detail. Also, we will delve into their processes and their pros and cons to help you choose the right approach for data projects with confidence.
Understanding the data integration process and the role of ETL and ELT
Since a data integration solution involves transferring or accessing data from one system to another, it requires a method to access data that can also orchestrate the movement, curation, and transformation of data. However, the specific techniques that businesses may use for data integration depend on the following factors:
- Data volume, velocity, and variety
- Number and type of data sources and destinations
- Requirements or desire to preserve historical data for future (unknown) use cases
- Data engineering resources, skill levels, and time available
- Available toolsets and technologies (cloud provider, vendor tools, IT resources)
- Data security and compliance requirements
The most common process within data integration is data ingestion (extraction or access), where one source system regularly ingests data into or accesses data from another system. Integrating data, also often requires data cleansing, validation, and enrichment to prepare data for analysis.
As an example of how the approaches differ in performing similar tasks, ETL and ELT approach data cleansing in the following manner. ETL (extract, transform, load) cleans data before storing (loading) data for future use, while ELT (extract, load, transform) stores data first and then cleans it.
While these differences may seem minor they are not. For example, cleansing or changing data before storing it impacts the potential future use of historical source system data. After the data modification, it is no longer an accurate point-in-time representation of the source data.
Conversely, storing the data in its raw form, without changes, preserves all data for future use cases. For example, you may need a data column only in the future for a new yet unplanned analytics solution. Another example would be a machine learning experiment that uses all historical data across a wide range of time.
While both integration methods perform similar pivotal tasks, the fundamental differences between the two methods have significant implications for data processing, storage, and analytics.
What is the ETL approach?
ETL is the acronym for Extract, Transform, and Load. It is a traditional approach to integrating data that comprises three main operations:
- Extracting and gathering data from various source systems, including databases, applications, files, APIs, or other systems.
- Transforming data into a standardized format. The transformation includes cleansing, aggregation, and reconstruction to ensure data usability.
- Loading into a target data warehouse, where it can be stored for analysis, reporting, or decision-making purposes.
What is the modern ELT approach?
The modern ELT (extract, load, transform) is a different approach to data integration. Unlike ETL, the ELT approach does not require data transformation before loading into the target system. Data is extracted from one system, loaded directly into the target system, and transformed afterward as needed within the data warehouse.
The primary difference between the ETL and ELT is the order through which the data transforms and loads. This facilitates immediate loading upon data capture, followed by transformation for analysis purposes. Moreover, compared to ELT, it reduces the time to extract and load data and allows data engineers to work with the transformed data directly in the target system using a wide selection of tools.
Cloud-based data warehouses, such as Snowflake, Microsoft Azure, Redshift, and BigQuery, have made ELT approaches much easier to adopt. These platforms now facilitate large-scale transformations efficiently within the warehouse, which has widened the usage of the ELT approach with data lake solutions.
The ETL process explained
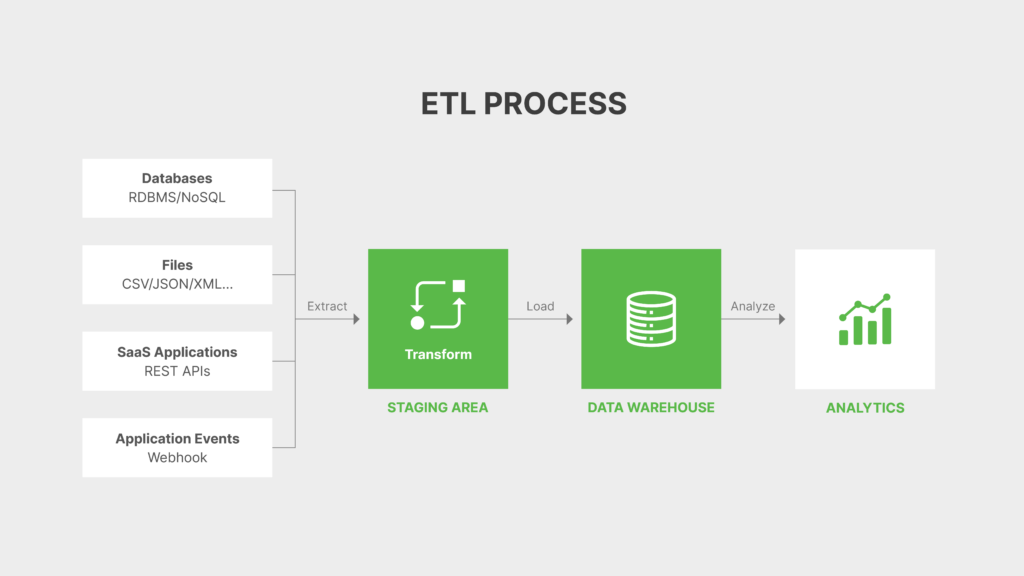
Extract
In the ETL process, the data is extracted using different methods, depending on the source systems and the volume of data. This includes full extraction (where all data is extracted every time), incremental extraction (where only new or modified data since the last extraction is captured), or real-time extraction (where data is continuously streamed in real-time).
Transform
In the transformation phase, the extracted data is transformed to ensure that it meets the requirements of the target system. Transformation involves cleansing, filtering, aggregating, enriching, or modifying the data to make it consistent, accurate, and usable for business decision-making.
Load
The last phase of the ETL process involves loading the transformed data into a new target system, typically a data warehouse or a data lake storage, both of which support large data volumes. Depending on the destination, different methods, such as full and incremental loading loads the data. The full approach involves loading all data regardless of whether it has already been previously loaded. While the incremental approach only loads new data that has become available after an initial full load.
Pros and cons of the ETL process
Although the ETL approach is a popular method for data integration, it’s not a one-size-fits-all solution. Let’s weigh the benefits and drawbacks of ETL to see if it aligns with your business data goals.
Pros of the ETL process
Data transformation
Allows comprehensive data transformation, cleaning, and enrichment before loading into the target system.
Data quality assurance
Ensures data quality through validation and cleansing processes.
Schedule flexibility
Offers flexibility in scheduling data extraction, transformation, and loading tasks.
Cons of the ETL process
Complexity
Requires significant planning and design to identify all the transformation requirements before landing any data.
Latency
May introduce performance challenges as resources perform data transformations, prior to any loading processes. This can significantly increase the length of time required to complete data extraction.
Resource or cost intensive
Often consumes more resources due by using the same tool to perform extraction and transformation activity. For example, performing transformations using a Data Factory pipeline workflow vs using SQL once the data is loading into a database.
The ELT process explained
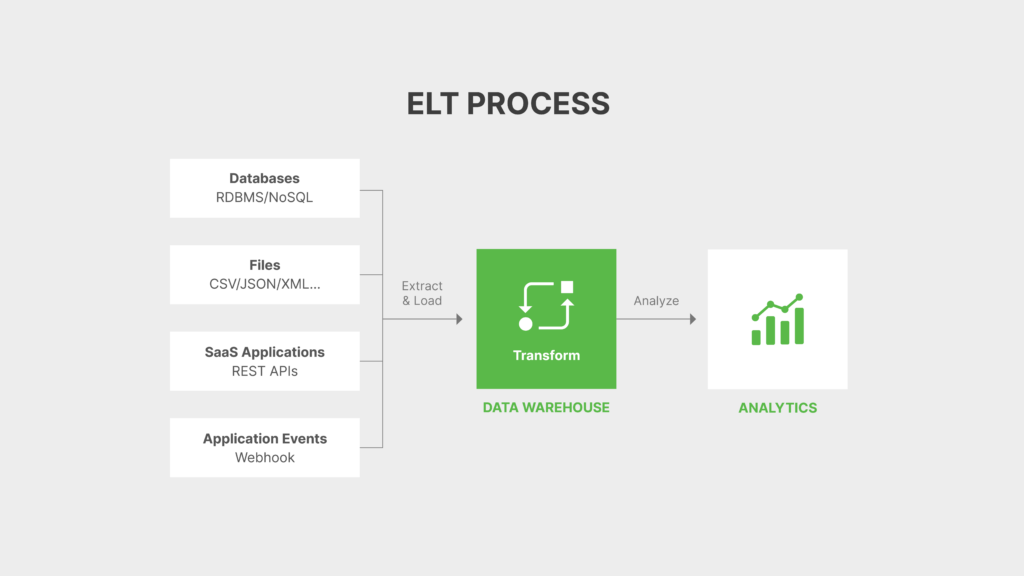
Extract
In the initial phase, just like ETL, ELT also involves extracting data from multiple sources, including databases, applications, files, APIs, and more. Depending on the requirements of the data integration task, you can perform extraction using various methods such as batch extraction, incremental extraction, or real-time extraction
Load
Following the extraction process, data loads into the target system. The system does not transform data; instead, it stores it in its raw form, representing the data from the source system at the time of extraction.
Transform
After loading the data, transformation tasks are performed. Transformations include data cleansing, enrichment, aggregation, or any other data processing tasks required to prepare the data for analysis or reporting.
Organizations can leverage the processing power, scalability, and diverse toolsets of modern data platforms by performing the transformation tasks within the target environment. This allows for faster and more efficient data processing, especially when dealing with large volumes of data.
Pros and cons of the ELT process
Like ETL, the ELT approach also possesses benefits and drawbacks for data integration solutions. Let’s explore the advantages and disadvantages of ELT to help you decide if it’s the right fit for your data journey.
Pros of the ELT process
Scalability
Offers scalability by leveraging the processing power diverse toolsets of modern data platforms.
Real-time insights
Enables real-time analysis and insights by loading raw data directly into the target system for immediate processing.
Cost efficiency
Reduces costs associated with tools used to perform extraction such as Data Factory. Offers more flexibility in choosing the tools used to perform transformations.
Data storage
Preserves data in its raw, historical form enabling future use cases.
Cons of the ELT process
Data volume
Stores all data in its raw form can require more storage than simply storing transformed data.
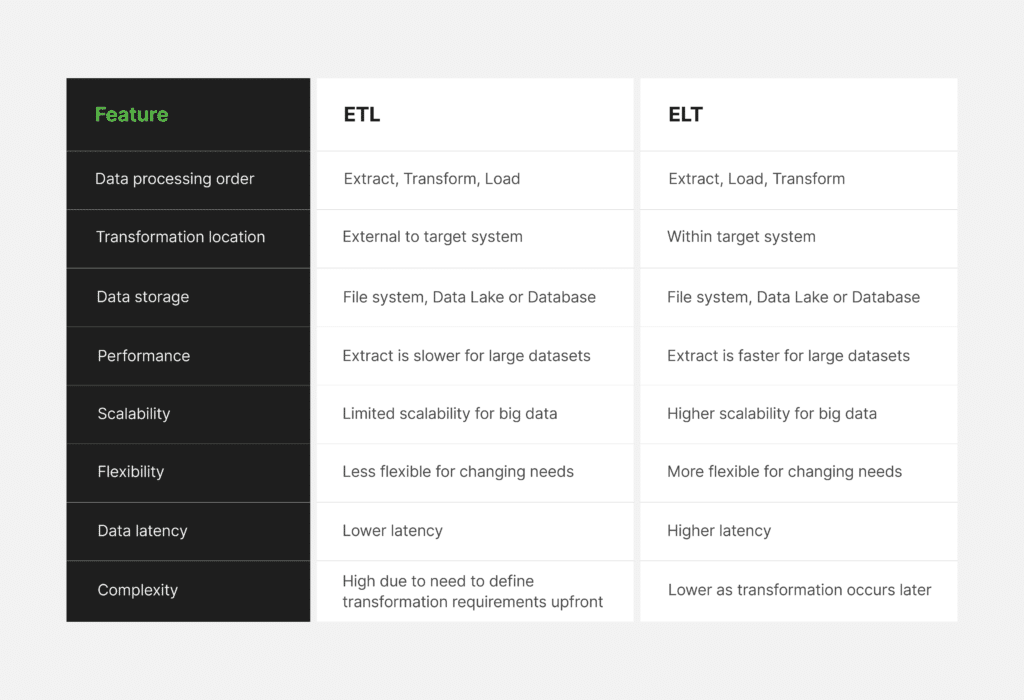
ETL vs ELT: A detailed comparative analysis
While organizations leverage ETL and ELT to cover a wide range of data needs, many still find it difficult to choose the best solution that fits their data management demands. To determine the right approach for data integration, we have prepared a table outlining the comparison between ETL and ELT across several features to help you make the right choice.
Choosing the right data integration strategy
The choice between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) strategies is not straightforward or clear-cut. There are various factors and considerations when deciding which approach to use for a particular data integration project.
The decision depends on factors such as the data’s source, its structure, the target system’s requirements, the desired level of data processing, future data requirements, and organizational goals. Therefore, it’s important to carefully evaluate the intricacies of each approach before making an informed decision.
Streamline your data management with Confiz
Since both ETL and ELT are robust cloud data integration strategies that give confidence to organizations for effortlessly managing their data projects, Confiz possesses deep expertise in both approaches to provide a solution according to your data management needs. Our proven track record of successful implementation and delivering effective data integration solutions has empowered businesses to acquire the maximum potential of their data assets.
Are you curious to know how Confiz can help you choose between ETL and ELT for your data needs? Speak to our experts at marketing@confiz.com and discover how we can power your business growth and success with our data management expertise.


