In the world of data and AI, large language models (LLMs) like GPT-3, GPT-4, and their competitors have garnered significant attention due to their remarkable capabilities in generating human-like text. These models are powered by billions (or even trillions) of parameters, enabling them to tackle a wide variety of natural language tasks with impressive accuracy. However, there’s a catch: these models are computationally expensive, slow to deploy, and difficult to scale.
This is where knowledge distillation comes in – a technique that allows us to compress large, powerful models into smaller, more efficient versions without sacrificing too much performance. In this article, we will explore the basics of LLMs and knowledge distillation, as well as how they’re being used to make state-of-the-art models more accessible and practical.
What are Large Language Models?
Large language models are a subset of deep learning models designed to understand and generate human language. These models, such as OpenAI’s GPT-3 (with 175 billion parameters) and Google’s BERT (with up to 340 million parameters in large variants), are based on the transformer architecture, which has become the standard for natural language processing (NLP) tasks.
More insights: Large Language Models explained: Learn what they are and how do they differ from GenAI
What is Knowledge Distillation?
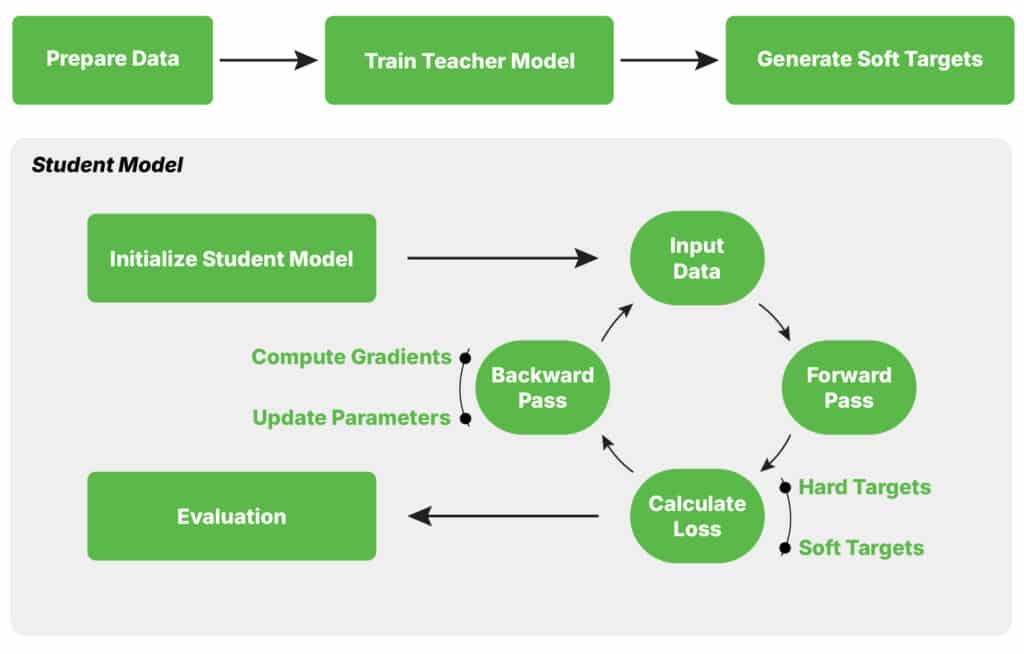
Knowledge distillation is a model compression technique that transfers knowledge from a large, cumbersome model (the “teacher”) to a smaller, more efficient model (the “student”). The objective is for the student model to approximate the teacher’s behavior and performance while requiring fewer parameters and less computational power.
The concept was first introduced by Geoffrey Hinton et al. (2015) in their paper “Distilling the Knowledge in a Neural Network.” The key idea is that the teacher model’s output probabilities (or logits) contain rich information that can guide the student model’s learning process. Instead of training the student model on the raw training data, the student is trained to mimic the teacher’s behavior on the same data.
How does Knowledge Distillation work?
Knowledge distillation is a machine learning technique where a smaller, simpler model (student) is trained to replicate the behavior of a larger, more complex model (teacher). The teacher model, which is typically a high-performing neural network, generates predictions or outputs that serve as a learning guide for the student. Instead of learning solely from labeled data, the student model learns by mimicking the teacher’s soft predictions, which provide richer information about the relationships between classes or features.
This approach helps the student model capture the essential knowledge from the teacher while being more lightweight and efficient, making it ideal for deployment in resource-constrained environments or for speeding up inference without significantly compromising accuracy.
Benefits of Knowledge Distillation
The primary benefits of this approach are:
- Smaller model size: The student model is much more lightweight, with fewer parameters.
- Faster inference: The reduced size of the student model enables faster processing, making it more suitable for deployment in resource-constrained environments.
- Lower energy consumption: By reducing the size of the model and the computational complexity, knowledge distillation can help mitigate the environmental impact of training large models.
Knowledge Distillation techniques
While the core principle of KD is relatively simple – transfer knowledge from a large model to a small one – there are various advanced techniques that improve the effectiveness. Below are some of the key approaches:
- Soft Target Distillation: The most common approach to Knowledge Distillation (KD) where the student model is trained to match the teacher model’s soft outputs (i.e., probabilities or logits), rather than the hard classification labels. This extra information helps the student model learn better generalizations. More details in following sections.
- Feature Distillation: Feature distillation involves transferring intermediate representations or activations from the teacher model to the student model. Instead of focusing on the final output layer, the student is encouraged to mimic the activations at various hidden layers of the teacher. This technique can help the student model capture richer representations and more complex features.
- Data-Free Distillation: This approach aims to train a smaller student model without needing the original training data. Instead, techniques like generating synthetic data or using activation functions to simulate the teacher’s behavior allow the student model to learn efficiently. This approach is especially useful when data privacy or availability is a concern.