
In the rapidly evolving world of data engineering, the emergence of Large Language Models (LLMs) is revolutionizing traditional processes. These advanced AI systems are not only transforming how data is extracted, cleaned, and transformed but also redefining the role of data engineers. From accelerating ETL development to enhancing data quality, LLMs introduce a level of efficiency and innovation previously unseen.
This blog delves into how traditional data engineering efforts are changing with the integration of LLMs, using an engaging narrative that follows a data engineer’s journey to harness the power of automation and intelligent frameworks.
Building the foundation of data transformation: A data engineer’s journey
In the vast and dynamic kingdom of DataLand, a determined data engineer named Goofy undertook a noble mission: to design a sophisticated and resilient data model that would become the cornerstone of the kingdom’s data pipeline. This endeavor aimed to transform raw data into valuable insights, empowering analysts and decision-makers throughout the realm.
The vision
Goofy’s goal was clear: to create a data model capable of handling the kingdom’s growing needs while ensuring accuracy, scalability, and efficiency. To accomplish this, Goofy relied on a comprehensive framework that included:
- Business Requirements Documents (BRD): To capture the kingdom’s needs and goals.
- KPI definition guidelines: To align the model with key performance indicators critical for the kingdom’s success.
The power of LLM assistance
Recognizing the complexities of the task, Goofy utilized Large Language Model (LLM) assistance to streamline the process. With LLM’s advanced capabilities, Goofy was able to enhance collaboration, automate repetitive tasks, and ensure precision in building the data model.
To achieve success, Goofy followed a structured delivery model, with tailored support provided at each phase of the journey. This systematic approach ensured that every aspect of the data model was thoughtfully planned and executed.
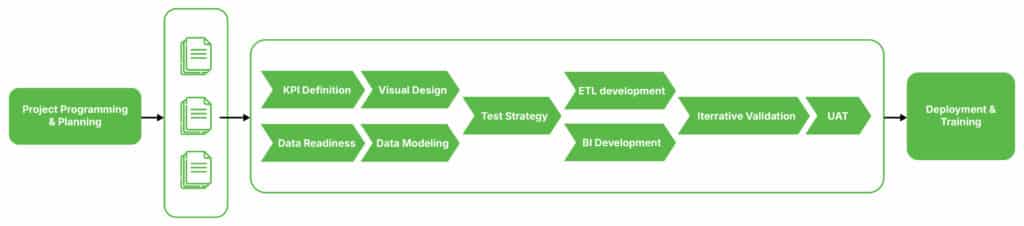
The call to adventure: Defining data transformation
Goofy’s mission was no small feat. It required:
- Defining detailed data transformation rules
- Adhering to stringent data quality standards
- Developing a sophisticated data model is essential for the future of DataLand’s analytics
The integrity and reliability of the data model were crucial for empowering analysts and decision-makers throughout the realm.
Discovery of the magical artifacts: Source Matrix (SMX) and documentation
As Goofy navigated the complex landscape of ETL (Extract, Transform, Load) development, he encountered two powerful artifacts.
1: The Source Matrix (SMX)
A cornerstone of the data engineering process, the SMX serves as a comprehensive blueprint that defines how data should be transformed, mapped, and validated throughout the pipeline. It ensures consistency, transparency, and ease of maintenance. The Source Matrix includes:
- Transformation rules: Guidelines for converting raw data into its refined state.
- Mapping schema: A blueprint mapping source fields to target destinations.
- Validation dimensions: Six principles ensuring data quality:
- Completeness: Every record must be accounted for.
- Uniqueness: Eliminate duplicate records.
- Consistency: Data values remain uniform across sources.
- Validity: Data adheres to predetermined standards.
- Accuracy: Data represents the truth of the real world.
- Timeliness: Data is relevant and up-to-date.
2: Supporting documentation
Documents like the Business Requirements Document (BRD) and KPI definitions provided critical context for the data model’s purpose and requirements.










